Z3 is most useful after a verifier has been lifted into precise expressions. The hard part is rarely calling s.check(); it is matching the binary’s types, operation order, shifts, and truncation points.
This post starts with a small fixed-width checker, then moves to symbolic table lookups, debugging, optimization, and a larger practice challenge.
1. Basic Example
// cc -O2 -std=c11 -Wall -Wextra -o z3_basic z3_basic.c#include <stdint.h>#include <stdio.h>#include <string.h>
static uint8_t rol8(uint8_t v, unsigned r) { r &= 7u; return (uint8_t)((v << r) | (v >> ((8u - r) & 7u)));}
int main(void) { char buf[128] = {0}; if (!fgets(buf, sizeof(buf), stdin)) { return 1; }
size_t len = strcspn(buf, "\n"); if (len != 24) { puts("no"); return 1; }
uint8_t x[24]; memcpy(x, buf, 24);
for (int i = 0; i < 24; i++) { if (x[i] < 0x20 || x[i] > 0x7E) { puts("no"); return 1; } }
uint32_t v = 0x13579BDFu; for (int i = 0; i < 24; i++) { v = (v + ((uint32_t)(x[i] ^ 0x5Au) * (uint32_t)(i + 3))) ^ (v >> 7); v = v + 0x1234u; }
if ((uint8_t)(x[3] + x[8] - x[15]) != 0xA4u) { puts("no"); return 1; }
if ((uint8_t)(rol8(x[10], 3) ^ x[1]) != 0x2Cu) { puts("no"); return 1; }
if (v != 0x135A0D76u) { puts("no"); return 1; }
puts("ok"); return 0;}Formula
uint32_t v = 0x13579BDFu;for (int i = 0; i < 24; i++) { v = (v + ((uint32_t)(x[i] ^ 0x5Au) * (uint32_t)(i + 3))) ^ (v >> 7); v = v + 0x1234u;}if ((((uint32_t)x[3] + x[8] - x[15]) & 0xFFu) != 0xA4u) return 0;if (((rol8(x[10], 3) ^ x[1]) & 0xFFu) != 0x2Cu) return 0;if (v != 0x135A0D76u) return 0;The transcription keeps the same operation order as the checker. The extra parentheses around the two byte conditions are important: in C, equality binds more tightly than bitwise & or ^. The final accumulator target, 0x135A0D76, comes from the checker and should be modeled as a fixed constant.
The corresponding Z3 model needs the same widths and conversions.
- Store each symbolic input byte as
BitVec(8). - Store the accumulator as
BitVec(32). - Zero-extend
x[i]before the 32-bit multiplication and addition. - Use
LShRfor the logical right shift ofuint32_t. - Remember that 32-bit bit-vector arithmetic already wraps modulo .
The basic recurrence is:
Here, is 0x13579BDF, is 0x5A, and is 0x1234. The shift in the first equation is logical because is unsigned.
The remaining conditions are:
is 0xA4, is 0x2C, and is 0x135A0D76.
Now the expressions can be translated directly into Z3.
XOR and fixed rotations are linear over , while XOR with a constant is affine. Modular addition introduces carry bits, so the complete recurrence is not a simple linear system. A bit-vector SMT model preserves those carries directly.
Modeling
from z3 import *
def rol8(v, r): return ((v << r) | LShR(v, 8 - r)) & 0xFF
x = [BitVec(f'x{i}', 8) for i in range(24)]
def build_base_solver(): s = Solver()
# Restrict the search to printable ASCII. for i in range(24): s.add(UGE(x[i], 0x20), ULE(x[i], 0x7E))
v = BitVecVal(0x13579BDF, 32)
for i in range(24): xi = ZeroExt(24, x[i]) v = (v + (xi ^ 0x5A) * (i + 3)) ^ LShR(v, 7) v = v + 0x1234
return s, v
# Define the local conditions.sum_cond = (ZeroExt(24, x[3]) + ZeroExt(24, x[8]) - ZeroExt(24, x[15])) & 0xFF == 0xA4rot_cond = (rol8(x[10], 3) ^ x[1]) == 0x2C
# Debug each optional condition with a fresh solver.checks = [ ("range", And([UGE(x[i], 0x20) for i in range(24)] + [ULE(x[i], 0x7E) for i in range(24)])), ("sum", sum_cond), ("rot", rot_cond),]
for name, cond in checks: s_test, _ = build_base_solver() s_test.add(cond) print(name, s_test.check())
# Solve the complete checker using the target from the binary.s, v = build_base_solver()s.add(sum_cond)s.add(rot_cond)s.add(v == BitVecVal(0x135A0D76, 32))
if s.check() == sat: m = s.model() model_values = [m.eval(xi, model_completion=True) for xi in x] candidate = bytes(value.as_long() for value in model_values) print(candidate)
# Block this model and ask whether another solution exists. s.push() s.add(Or([xi != value for xi, value in zip(x, model_values)])) print("unique" if s.check() == unsat else "multiple solutions") s.pop()else: print("unsat")This checker is intentionally underconstrained. Z3 returns one valid printable candidate, but the blocking clause finds another model. If a challenge expects a unique flag, add every format and cross-byte constraint present in the binary instead of assuming the first model is the intended answer.
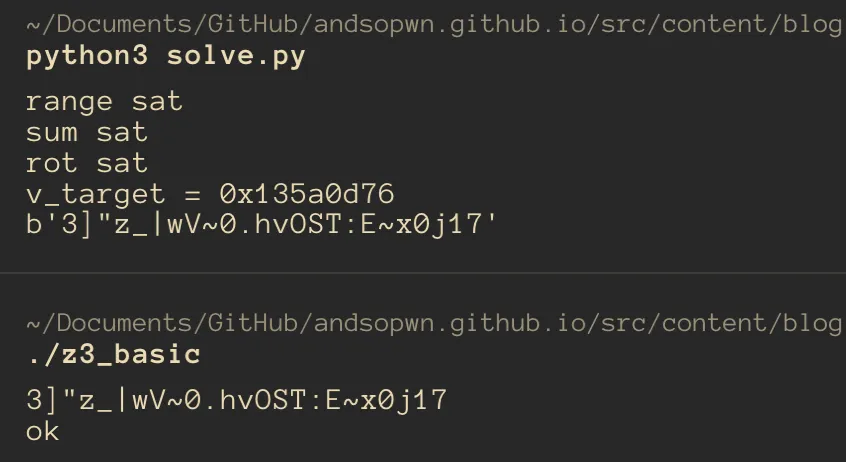
The screenshot below records the one-time setup used to construct this synthetic example: a preliminary model produced 0x135A0D76, that value was placed in the C checker, and the resulting candidate was replayed against the compiled program. The finalized solver above starts from the checker constant, which is the workflow used when reversing a real binary. Because the checker has multiple solutions, the candidate bytes may also differ between runs or Z3 versions.
ZeroExt(24, x[i])converts an unsigned 8-bit byte into a 32-bit operand.LShR(v, 7)matches the logical shift of auint32_t;v >> 7in Z3 would be an arithmetic shift.- A 32-bit
BitVecwraps automatically. Use a mask orExtractwhere the binary actually truncates to a smaller width. - Z3Py can coerce many Python integers from context, but
BitVecVal(value, width)makes width-sensitive constants explicit.
2. Advanced Example
- Table lookup + mixed recurrence + aggregate checks
This pattern appears frequently in larger verifiers: a symbolic table lookup feeds a mixed accumulator, while several local conditions constrain selected bytes.
Input: 32 bytesRound:1) Substitute an input byte through a 256-byte table T2) Update a 32-bit accumulator v with XOR, ADD, and ROL3) Apply partial checks at selected positionsFinal: v == 0x7A3C91F2The lifted verifier has the following properties.
- A real S-box or permutation table makes direct algebraic inversion harder.
- Mixing rotate, XOR, and addition causes the accumulator expression to grow quickly.
- Multiple partial checks make a bad transcription become
unsat, often before the final condition is added.
The concrete table below,
T[i] = i ^ 0xA5, is intentionally simple and affine; it demonstrates symbolic lookup rather than S-box strength. In a real verifier, a nonlinear table combined with carry-producing addition is what defeats a straightforward linear solution.
Formula
Start with a fixed initial accumulator such as 0xC0FFEE00.
Here, is a round constant such as 0x13, and the entire result wraps to 32 bits.
One intermediate condition is:
where is a fixed byte from the checker.
Modeling
from z3 import *
def rol32(v, r): return ((v << r) | LShR(v, 32 - r)) & 0xFFFFFFFF
# Deliberately simple lookup table for the modeling example.T = [i ^ 0xA5 for i in range(256)]
x = [BitVec(f'x{i}', 8) for i in range(32)]s = Solver()
# Printablefor i in range(32): s.add(UGE(x[i], 0x20), ULE(x[i], 0x7E))
def Tlookup(b): return Sum([If(b == k, BitVecVal(T[k], 8), BitVecVal(0, 8)) for k in range(256)])
v = BitVecVal(0xC0FFEE00, 32)
for i in range(32): # Symbolic T[x[i]] using a deliberately naive 256-way expression. tval = Tlookup(x[i]) t32 = ZeroExt(24, tval)
v = rol32(v, 5) + (t32 ^ BitVecVal(i * 0x13, 32)) + LShR(v, 3)
# Intermediate checkss.add((Tlookup(x[7]) + Tlookup(x[19]) - Tlookup(x[23])) & 0xFF == 0xB6)s.add((x[5] ^ x[11] ^ x[29]) == 0x2D)s.add(((x[2] + x[9] + x[17]) & 0xFF) == 0x90)
# Final conditions.add(v == 0x7A3C91F2)
if s.check() == sat: m = s.model() ans = bytes([m.eval(x[i], model_completion=True).as_long() for i in range(32)]) print(ans)> python3 solve2.pyb'r0&,f~D0v!p/zl"9GI\\CV86`xz `;|c.'This is one satisfying model. Because the constraints are not unique, the exact bytes may change across Z3 versions or solver configurations. Use the blocking-clause pattern from the basic example if the challenge requires proof that the result is unique.
- Table Lookup with
Array
The first model builds a 256-way If expression for every lookup. A Z3 Array represents the same concrete table more directly.
arr = K(BitVecSort(8), BitVecVal(0, 8))for k, value in enumerate(T): arr = Store(arr, BitVecVal(k, 8), BitVecVal(value, 8))
tval = Select(arr, x[i])Starting from K gives every array index a defined value before the 256 stores are applied. Select avoids rebuilding the long conditional expression at each use. This usually reduces expression size, although the solver’s final performance still depends on the surrounding constraints.
3. Common Modeling Faults
Most failed solver scripts come from semantic mismatches rather than Z3 itself.
- Signed versus unsigned values
Do not assume that a decompiler’s char is unsigned. Check the load, extension, comparison, and shift instructions. Use ZeroExt for an unsigned widening conversion and SignExt for a signed one. Z3’s overloaded comparisons on bit-vectors are signed, so use ULT, ULE, UGT, and UGE for unsigned comparisons.
- Operation order
(a + b) ^ c and a + (b ^ c) are different expressions. Follow the assembly or decompiler expression in execution order, including every cast and temporary.
- Integer promotion and truncation
In C, uint8_t operands are normally promoted to int before arithmetic. The result is truncated only when it is cast or stored back into a narrower object. Model the promoted expression at the width used by the binary, then truncate at the exact assignment or cast; using only 8-bit expressions everywhere can hide carries too early.
- Logical versus arithmetic right shift
An unsigned C right shift maps to LShR. Z3’s >> operator on a bit-vector is arithmetic and preserves the sign bit. For rotations, use RotateLeft or RotateRight when the count is constant, or reproduce the binary’s masked variable-count expression explicitly.
4. Debugging
- Add one condition at a time
s.push()s.add(condition_1)print(s.check())s.pop()push() and pop() preserve the base model while testing one extra condition. Repeating this narrows the first point at which the model becomes inconsistent.
A system containing only XOR and fixed rotations may admit a direct linear treatment. Addition with carries and nonlinear table lookups are the point where a bit-vector solver becomes much more convenient.
- Test a
checkslist with fresh solvers
Do not add every optional condition to one already-constrained solver and then try to test them individually. Build a fresh base solver for each check so earlier optional constraints do not contaminate the result.
checks = [ ("range", And([UGE(x[i], 0x20) for i in range(24)] + [ULE(x[i], 0x7E) for i in range(24)])), ("sum", sum_cond), ("rot", rot_cond),]
for name, cond in checks: s_test, _ = build_base_solver() s_test.add(cond) print(name, s_test.check())If range is unsat, the base input-domain model is contradictory. If sum or rot becomes unsat, recheck that expression’s operation order, width, and overflow behavior. This isolates a bad condition before the full recurrence hides it.
- Check intermediate values
If IDA or Ghidra provides a concrete intermediate value, constrain the symbolic expression captured at that exact program point.
s.add(checkpoint_v == BitVecVal(0x1234ABCD, 32))If this is unsat, the mismatch occurs at or before that checkpoint. Move the checkpoint earlier until the symbolic and concrete executions agree.
- Replay the model
m = s.model()candidate = bytes(m.eval(xi, model_completion=True).as_long() for xi in x)print(candidate)Pass the candidate to the original binary. A sat result validates the model you wrote, not the transcription from the binary.
5. Optimization
- Restrict the domain: if the binary accepts only uppercase letters and digits, encode that exact range immediately.
- Remove proven redundancy: drop a condition only after confirming that it is implied by the remaining constraints.
- Reuse expressions: build repeated table lookups and round expressions once instead of reconstructing them.
- Partition independent constraints: solve separable byte groups first, but do not split a recurrence or cross-byte condition arbitrarily.
Solver time depends on expression structure. Smaller domains, shared subexpressions, and early local checks often help more than changing tactics blindly.
Z3 is not a substitute for reversing. The decisive skill is still extracting the correct expression with the correct types, widths, and overflow behavior. Once those semantics are right, even a dense verifier becomes manageable.
6. Practice
#include <stdio.h>#include <stdint.h>#include <string.h>
static uint32_t lcg_next(uint32_t *s) { *s = (*s * 1664525u) + 1013904223u; return *s;}
static uint32_t rotl32(uint32_t x, unsigned r) { r &= 31u; return (x << r) | (x >> ((32u - r) & 31u));}
static uint64_t rotl64(uint64_t x, unsigned r) { r &= 63u; return (x << r) | (x >> ((64u - r) & 63u));}
static uint32_t read_le32(const uint8_t *p) { return (uint32_t)p[0] | ((uint32_t)p[1] << 8) | ((uint32_t)p[2] << 16) | ((uint32_t)p[3] << 24);}
static void gen_perm(uint8_t perm[48]) { uint32_t s = 0xA3C59AC3u; for (int i = 0; i < 48; i++) { perm[i] = (uint8_t)i; } for (int i = 47; i > 0; i--) { s = lcg_next(&s); uint32_t j = s % (uint32_t)(i + 1); uint8_t tmp = perm[i]; perm[i] = perm[j]; perm[j] = tmp; }}
static void gen_sbox(uint8_t sbox[24]) { uint32_t s = 0xC3D2E1F0u; for (int i = 0; i < 24; i++) { s = lcg_next(&s); sbox[i] = (uint8_t)s; }}
static void gen_keys(uint32_t keys[18]) { uint32_t s = 0x1BADB002u; for (int i = 0; i < 18; i++) { s = lcg_next(&s); keys[i] = s; }}
static void gen_tbox(uint32_t tbox[16]) { uint32_t s = 0xB16B00B5u; for (int i = 0; i < 16; i++) { s = lcg_next(&s); tbox[i] = s; }}
static uint32_t feistel_f(uint32_t x, uint32_t k, const uint32_t tbox[16]) { uint32_t y = x + k; uint32_t z = rotl32(x ^ k, y & 31u); uint32_t m = (x * 0x045d9f3bu) ^ rotl32(y, 7); uint32_t t = tbox[(x ^ k) & 0xFu]; uint32_t f = z + m + t + 0x9e3779b9u; f ^= (f >> 16); f += rotl32(f, 3); return f;}
static int check_ascii(const uint8_t *buf, size_t len) { for (size_t i = 0; i < len; i++) { if (buf[i] < 0x20 || buf[i] > 0x7e) { return 0; } } return 1;}
static int check_stream(const uint8_t *buf) { static const uint8_t stream_expected[48] = { 0x24, 0xd9, 0x4e, 0x85, 0x4f, 0x7d, 0x68, 0xb7, 0x08, 0x22, 0x1e, 0x4d, 0xd7, 0xdf, 0x99, 0x3d, 0xac, 0xfe, 0xd4, 0x06, 0x68, 0xfd, 0x21, 0x68, 0x42, 0xe3, 0x4d, 0x71, 0xec, 0x7d, 0xe6, 0xf4, 0x5a, 0x18, 0x9e, 0xef, 0x9c, 0x5b, 0x0d, 0x3e, 0x60, 0x78, 0x91, 0xfe, 0xc1, 0x93, 0x63, 0xf5 }; uint32_t s = 0xD00DFEEDu; for (int i = 0; i < 48; i++) { s = lcg_next(&s); uint8_t ks = (uint8_t)(s >> 24); if ((uint8_t)(buf[i] ^ ks) != stream_expected[i]) { return 0; } } return 1;}
static int check_perm_sbox(const uint8_t *buf) { static const uint8_t perm_expected[24] = { 0xe3, 0xc0, 0xe9, 0x57, 0x6c, 0x97, 0xa9, 0xac, 0x27, 0xee, 0x52, 0x13, 0x52, 0x01, 0x15, 0x22, 0xe4, 0x02, 0x4e, 0x09, 0x70, 0xb0, 0x08, 0x9c }; uint8_t perm[48]; uint8_t sbox[24]; gen_perm(perm); gen_sbox(sbox); for (int i = 0; i < 24; i++) { uint8_t v = (uint8_t)(buf[perm[i]] ^ sbox[i]); if (v != perm_expected[i]) { return 0; } } return 1;}
static int check_feistel(const uint8_t *buf) { static const uint32_t expL[6] = { 0xc808b416u, 0xe9100223u, 0x5031e4ccu, 0x610df482u, 0x22c9a088u, 0x05f105c9u }; static const uint32_t expR[6] = { 0xa217b24bu, 0xd5881d02u, 0x9f8c09e4u, 0x9605e10au, 0xe4fb1a56u, 0xb20a9001u }; uint32_t keys[18]; uint32_t tbox[16]; gen_keys(keys); gen_tbox(tbox);
for (int blk = 0; blk < 6; blk++) { const uint8_t *p = buf + (blk * 8); uint32_t L = read_le32(p); uint32_t R = read_le32(p + 4); for (int r = 0; r < 3; r++) { uint32_t k = keys[(blk * 3) + r]; uint32_t f = feistel_f(R, k, tbox); uint32_t newL = R; R = L ^ f; L = newL; } if (L != expL[blk] || R != expR[blk]) { return 0; } } return 1;}
static int check_hash(const uint8_t *buf) { const uint64_t expected = 0x8a7ad627100d088aULL; uint64_t h = 0x0123456789ABCDEFULL; for (int i = 0; i < 48; i++) { h ^= (uint64_t)(buf[i] + i); h *= 0x100000001B3ULL; h = rotl64(h, 17); h ^= (h >> 23); } return h == expected;}
static int check_sums(const uint8_t *buf) { const uint32_t sum_even_expected = 0x0000d028u; const uint32_t sum_odd_expected = 0x0000e5e8u; const uint8_t xor_expected = 0x60u;
uint32_t sum_even = 0; uint32_t sum_odd = 0; uint8_t xor_all = 0;
for (int i = 0; i < 48; i++) { if ((i & 1) == 0) { sum_even += (uint32_t)buf[i] * (uint32_t)(i + 1); } else { sum_odd += (uint32_t)buf[i] * (uint32_t)(i + 1); } xor_all ^= buf[i]; } return sum_even == sum_even_expected && sum_odd == sum_odd_expected && xor_all == xor_expected;}
int main(void) { char input[128]; if (!fgets(input, sizeof(input), stdin)) { return 1; } size_t len = strcspn(input, "\r\n"); input[len] = '\0';
if (len != 48) { puts("wrong"); return 0; }
const uint8_t *buf = (const uint8_t *)input; if (!check_ascii(buf, len)) { puts("wrong"); return 0; }
if (check_stream(buf) && check_perm_sbox(buf) && check_feistel(buf) && check_hash(buf) && check_sums(buf)) { puts("correct"); } else { puts("wrong"); } return 0;}- The input must be exactly 48 printable ASCII bytes.
- An LCG-derived keystream XOR constrains every byte.
- Permutation and S-box XOR constraints cover 24 selected positions.
- Six 8-byte blocks pass through three Feistel rounds and must match the expected left and right words.
- A rolling hash, weighted sums, and a final XOR provide independent consistency checks.
Model the 48 input bytes as bit-vectors and translate each checker function at its native width.
from z3 import *
A = 1664525C = 1013904223
def lcg(x): return (x * A + C) & 0xFFFFFFFF
def gen_perm(): state = 0xA3C59AC3 perm = list(range(48)) for i in range(47, 0, -1): state = lcg(state) j = state % (i + 1) perm[i], perm[j] = perm[j], perm[i] return perm
def gen_sbox(): state = 0xC3D2E1F0 sbox = [] for _ in range(24): state = lcg(state) sbox.append(state & 0xFF) return sbox
def gen_keys(): state = 0x1BADB002 keys = [] for _ in range(18): state = lcg(state) keys.append(state) return keys
def gen_tbox(): state = 0xB16B00B5 tbox = [] for _ in range(16): state = lcg(state) tbox.append(state) return tbox
perm_expected = [ 0xe3, 0xc0, 0xe9, 0x57, 0x6c, 0x97, 0xa9, 0xac, 0x27, 0xee, 0x52, 0x13, 0x52, 0x01, 0x15, 0x22, 0xe4, 0x02, 0x4e, 0x09, 0x70, 0xb0, 0x08, 0x9c]
stream_expected = [ 0x24, 0xd9, 0x4e, 0x85, 0x4f, 0x7d, 0x68, 0xb7, 0x08, 0x22, 0x1e, 0x4d, 0xd7, 0xdf, 0x99, 0x3d, 0xac, 0xfe, 0xd4, 0x06, 0x68, 0xfd, 0x21, 0x68, 0x42, 0xe3, 0x4d, 0x71, 0xec, 0x7d, 0xe6, 0xf4, 0x5a, 0x18, 0x9e, 0xef, 0x9c, 0x5b, 0x0d, 0x3e, 0x60, 0x78, 0x91, 0xfe, 0xc1, 0x93, 0x63, 0xf5]
expL = [0xc808b416, 0xe9100223, 0x5031e4cc, 0x610df482, 0x22c9a088, 0x05f105c9]expR = [0xa217b24b, 0xd5881d02, 0x9f8c09e4, 0x9605e10a, 0xe4fb1a56, 0xb20a9001]
hash_expected = 0x8a7ad627100d088asum_even_expected = 0x0000d028sum_odd_expected = 0x0000e5e8xor_expected = 0x60
b = [BitVec(f"b{i}", 8) for i in range(48)]s = SolverFor("QF_AUFBV")
for i in range(48): s.add(UGE(b[i], 0x20), ULE(b[i], 0x7e))
state = 0xD00DFEEDfor i in range(48): state = lcg(state) ks = (state >> 24) & 0xFF s.add(b[i] ^ BitVecVal(ks, 8) == BitVecVal(stream_expected[i], 8))
perm = gen_perm()sbox = gen_sbox()for i in range(24): s.add(b[perm[i]] ^ BitVecVal(sbox[i], 8) == BitVecVal(perm_expected[i], 8))
keys = gen_keys()tbox = gen_tbox()tbox_arr = K(BitVecSort(4), BitVecVal(0, 32))for i, v in enumerate(tbox): tbox_arr = Store(tbox_arr, BitVecVal(i, 4), BitVecVal(v, 32))
def rotl32_var(x, r): r = r & BitVecVal(31, 32) inv = (-r) & BitVecVal(31, 32) return (x << r) | LShR(x, inv)
def feistel_f(x, k): y = x + k z = rotl32_var(x ^ k, y) m = (x * BitVecVal(0x045d9f3b, 32)) ^ RotateLeft(y, 7) idx = Extract(3, 0, x ^ k) t = Select(tbox_arr, idx) f = z + m + t + BitVecVal(0x9e3779b9, 32) f = f ^ LShR(f, 16) f = f + rotl32_var(f, BitVecVal(3, 32)) return f
def pack_le32(bs): return Concat(bs[3], bs[2], bs[1], bs[0])
for blk in range(6): off = blk * 8 L = pack_le32(b[off:off+4]) R = pack_le32(b[off+4:off+8]) for r in range(3): k = BitVecVal(keys[blk * 3 + r], 32) f = feistel_f(R, k) L, R = R, L ^ f s.add(L == BitVecVal(expL[blk], 32)) s.add(R == BitVecVal(expR[blk], 32))
h = BitVecVal(0x0123456789ABCDEF, 64)for i in range(48): h = h ^ (ZeroExt(56, b[i]) + BitVecVal(i, 64)) h = h * BitVecVal(0x100000001B3, 64) h = RotateLeft(h, 17) h = h ^ LShR(h, 23)s.add(h == BitVecVal(hash_expected, 64))
sum_even = BitVecVal(0, 32)sum_odd = BitVecVal(0, 32)xor_all = BitVecVal(0, 8)for i in range(48): if i % 2 == 0: sum_even = sum_even + ZeroExt(24, b[i]) * (i + 1) else: sum_odd = sum_odd + ZeroExt(24, b[i]) * (i + 1) xor_all = xor_all ^ b[i]
s.add(sum_even == BitVecVal(sum_even_expected, 32))s.add(sum_odd == BitVecVal(sum_odd_expected, 32))s.add(xor_all == BitVecVal(xor_expected, 8))
if s.check() != sat: print("unsat") raise SystemExit(1)
m = s.model()candidate = "".join(chr(m.eval(b[i]).as_long()) for i in range(48))print(candidate)
lia = SolverFor("QF_LIA")x = [Int(f"x{i}") for i in range(48)]for i in range(48): lia.add(x[i] == ord(candidate[i])) lia.add(x[i] >= 0x20, x[i] <= 0x7e)
lia.add(Sum([x[i] * (i + 1) for i in range(0, 48, 2)]) == sum_even_expected)lia.add(Sum([x[i] * (i + 1) for i in range(1, 48, 2)]) == sum_odd_expected)
assert lia.check() == sat
xor_val = 0for ch in candidate: xor_val ^= ord(ch)assert xor_val == xor_expectedIn this particular checker, the stream equations already determine all 48 bytes. The permutation, Feistel, hash, sum, and XOR constraints therefore act as independent validation of both the candidate and the transcription. The final QF_LIA block does not discover a second solution; it rechecks the weighted sums after fixing every integer to the candidate byte.
- Top 3 Solver (Discord @badabodaa)
@Greedun RubiyaLab 2025.12.27@Gunter RubiyaLab 2025.12.27